interpretation
Predicting outcomes in fantasy football turns out to be an excercize of high variance. Coming from the regression iterations, draft_capital and ln(draft) predictor variables have R2 anywhere from 0.1 to 0.3; fantasy_points_per_game fits better, typically 0.3-0.5, tho many data analysts would consider this low too. It all depends. Statistics is a subtle language.
The regression summary displays R2 in the top right corner.
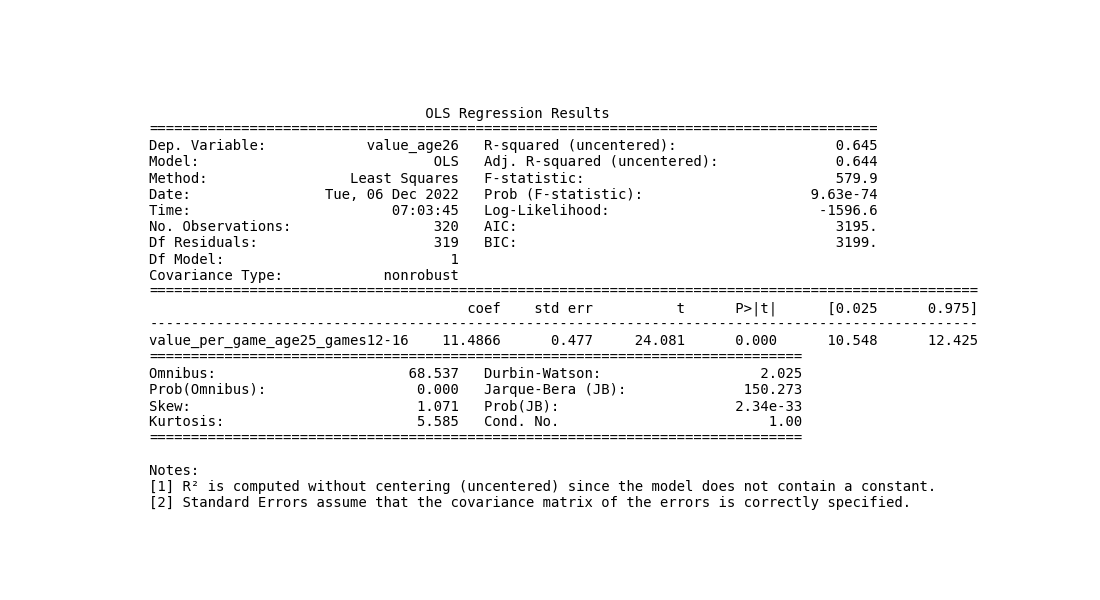
But, found in the middle under P>|t|, the is just as important to regression as R2.
As a measure of , a P-value explains, generally speaking, the liklihood of whether or not a correlation exists.
A lower number means more likely.
For example, a P-value of .05 can be thought to mean there's a 95% chance the independent and dependent variables have association;
tho, implies nothing of .
The P-value is related to , but also to the number of observations. Data with wide ranging values requires a lot of data points. Fortunately, here that happens to be the case. As such, in terms of , this model provides more accuracy than precision. If I were to provide with each trade, they would be lower than most people would imagine. Realize the trade process works as long term by accumulation, but will be wrong perhaps 40% of the time. I liken it to poker, where chasing an inside straight will occasionally win, but loses on average.
Lastly, I feel the need to point out what is perhaps obvious, that there is more to football than can be captured . A computer is an extreme version of an autistic savant, like , unable to understand the meaning of things. There is a ton of qualitative information to process in this hobby, the deciphering of such you could call the art of fantasy. The individual must balance his own assessment of real life with that of the quantitative process offered by this trading model.